It Happened One Frame: incredibly accurate video content search with OpenAI CLIP
I love movies, so as a fun exercise for my fast.ai course, I created an app - which you can use here - that lets you search frames from YouTube videos based on the text you type in. It’s named “It Happened One Frame”, in tribute to the classic 1934 romantic comedy “It Happened One Night”.
To use this app, all you need is the link to a Youtube video. For example, you could search “Macaulay Culkin screams with hands on his cheeks” in a Home Alone movie clip and get the screenshots that capture the most iconic scene in this classic.

This particular image is so popular that you can easily get it from a google search. But with the app, you will be able to search for any scene in any movie as long as you can describe it with words. It is extremely flexible and can handle a wide range of visual concepts: from people, objects and locations, to more abstract features such as emotions, vibes and religions. It recognizes public figures and comic book super heroes. So if you use the actors’ names in your search, very likely the app already knows who they are. Even if it does not recognize the name, it will be able to make a reasonably good guess based on the context of the query, as well as the race and gender of the name - the same way we humans would do. If your movie clip has subtitles, you can even include the content of the dialog in your search, e.g. you can search “Vizzini says inconceivable” in The Princess Bride. You can also give specific commands about how the frame was shot, using phrases such as “close-up shot” or “a overhead shot”. There are so many ways you can formulate your search query.
I have had a lot of fun using this app to revisit some of my favorite movie scenes. The results are astonishingly accurate. It almost feel like magic. I’m going to share some examples with you in this post. But firstly, I want to talk about the incredibly powerful model that made this magic happen - the CLIP model.
What is CLIP and why is it amazing?
CLIP is a model from Open AI that’s trained with hundreds of millions of images with their captions from the internet. It is trained to learn how semantically-related the texts are to the images. You will find its model architecture surprisingly simple: basically, you put each image and text pair through an image encoder and a text encoder respectively, and bring them into the same N-dimensional embedding space. From there you can calculate the cosine similarity between the two vectors. Its learning objective is to jointly train the image and text encoders in order to maximize the cosine similarity between the correct image and text pairs, and minimize the cosine similarity between the incorrect pairs at the same time.
A much more difficult question to answer is why CLIP is able to perform so well. Open AI released a second paper that dives deeper into the inner workings of the CLIP model via faceted feature visualization. You can read the full paper here. I will not go into its details in this article. But one amazing finding from this paper is that CLIP neurons are multimodal! It means its neurons fire to the same concept, regardless of whether it is in photographs, drawings, or text. For example, the “Spiderman” neuron in CLIP will respond to Spiderman in all forms: pictures of Spiderman, comic book drawings of Spiderman, or even images that contain the text “Spiderman”. It means that with CLIP, we will be able to leverage subtitles in our movie frame search. This capability is super handy because often times we want to find a scene based on a line that we remember from the movie. Obviously you can transcribe the audio into text and then perform a keyword search. But CLIP allows you to search for audio and visual content at the same time. It is able to develop a much more comprehensive understanding of the movie frames with semantic information from both the frame itself and the subtitles.
Natural language supervision allows CLIP to learn a much broader range of visual features when compared with traditional networks. Zero-shot CLIP significantly outperforms Resnet-50 in action recognization. Moreover, it’s able to understand abstract concepts that Resnet could not understand, such as emotions, seasons, and geography. It even understands pop culture, religion and art, as well as concepts in photography such as perspective and magnification. This allows our users to formulate intuitive search queries for practically anything they want to search.
Fun with the app
Yankee Doodle Dandy
Let’s start with a simple example. I want to find a very memorable scene in Yankee Doodle Dandy. It is toward the end of the movie: as James Cagney (portraying George M. Cohan) leaves the president’s office and walks down the stairs in White House, he suddenly starts to tap dance and improvises all the way to the bottom, without once looking down at his feet. It was really a magnificent scene. I searched “James Cagney dancing down the stairs” in this clip of Yankee Doodle Dandy’s final scene. And this is the result

My search query is simple. It includes a person (James Cagney), an object (stairs) and an action (dancing). While it is relatively easy for AI algorithms to identify objects, it’s more challenging to recognize actions. If you watch the clip, you can tell that Cagney started off by walking down the stairs, and then broke into a dance at 2:36. But it is not that easy to differentiate dancing from walking when you only look at a single frame. Looking at frames returned by the app, I, as a human, can’t confidently say whether he was dancing or walking in any of the 4 frames. But CLIP knows better - the timestamps on the upper left corner of each frame show that all these 4 frames are captured after 2:36, indicating that Cagney was indeed dancing in these frames. It is quite impressive!
Once upon a Time in America
I really like this beautiful scene from Once upon a Time in America, where the young Deborah (played by Jennifer Connelly) is practicing ballet dance in her parents’ restaurant. This clip I found only contains the dance sequence. I want to use it as an example to show you how you can search for frames from specific angels and perspectives.
Let’s first see what the result looks like when we simply search for “Deborah dancing”. You can see that all these shots are pretty close-up, and Debrah was facing the camera only half of the time.

Let’s see what happens if we search “Deborah facing the camera”. Look! Deborah is now facing the camera in all 4 frames

And of course, searching “a wide shot of Deborah practicing her ballet” will get you wider shots:) Now you can see Deborah is wearing a tutu, and she is dancing in a dusty storehouse. It’s stunning! isn’t it?

Paths of Glory
The ending of Paths of Glory holds a special place in my heart. It’s a movie about war. This particular scene took place in a bar, where a captured German girl was forced to sing for French soldiers. As she started to sing, the rowdy crowd became silent. The soldiers started to hum along and many of them teared up. I vividly remember how the camera moved from face to face and the soldiers’ facial expressions changed. This scene is incredibly emotional. I think it is a perfect example to test the app’s ability to identify emotions. And here are my results using this clip
It understands “rowdy”

It jointly understands emotion and action

When I searched for “audience quiets down and listens intently and respectfully to her plaintive voice”, it inferred that there was a girl singing. Not only did it find frames where the audience looked serious, it included the girl on stage facing the audience in all 4 frames.

And yeah, it definitely understands sadness
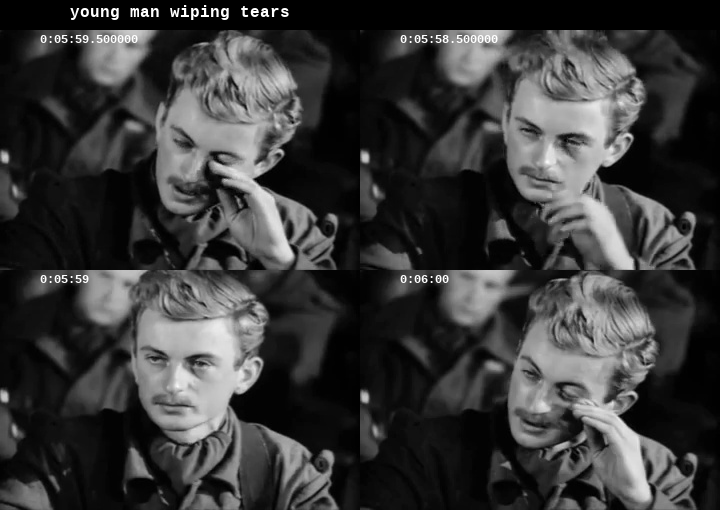

However, it does not seem to understand “sentimental”

Inglourious Basterds
Finally, we are going to play with this clip from Inglourious basterds - it has subtitles so we can include the content of dialog in our search!
But first, I want to know if it recognizes Brad Pitt. This is the result when I searched “Brad Pitt” - I think the answer is an astounding YES!

When I searched for “Landa sees Bridget’s left leg is wrapped in cast and asks her what happened”, I was able to find the exact frames where Landa asked Bridget “so what’s happened to your lovely leg?”

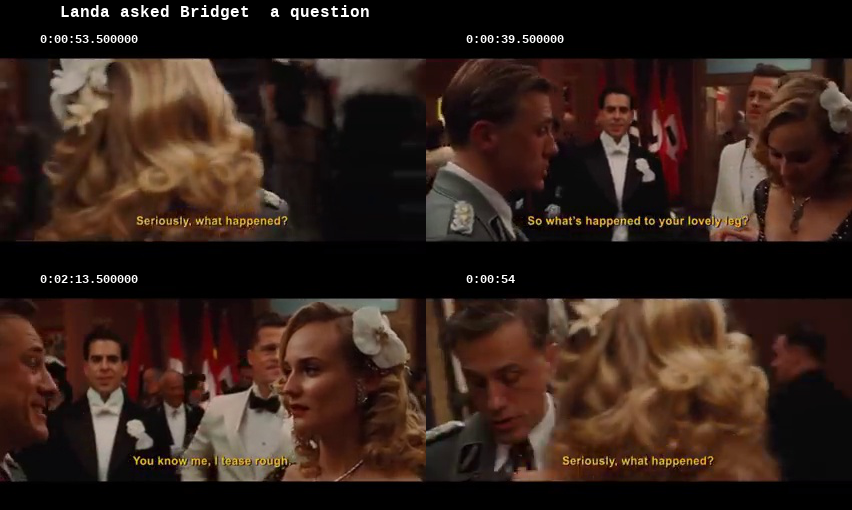
If I search “Landa asked Bridget a question”, 3 of the 4 frames in the results have a question mark in the subtitles. CLIP’s “question” neuron fires when it sees a question mark.
If I search “she introduce Brad Pitt as Italian stuntman”, it returned the exact frames where the subtitle says “This is a wonderfurl Italian stuntman, Enzo Gorlomi”. There is no way it’s able to identify Brad Pitt as the “stuntman” just based on the image without the ability to read subtitles robustly.

Now let’s make it even more fun! What if I search “Bridget introduced Brad Pitt as camera assistant Dominick”? This is a lie because she introduced Omar as the camera assistant, not Brad Pitt. And we already knew that the app recognizes Brad Pitt. What would it do now? Ohhh looks like it sees right through our trick :P

Conclusion
In this post, we’ve seen examples demonstrating how well CLIP understands what’s happening inside each frame of a movie. CLIP is truly an incredible and powerful model. Feel free to play with the app yourself and let me know what you found:)